大数据林子雨
大数据概述(from 厦门大学林子雨)
大数据产业:
| 产业链环节 | 包含内容 |
|---|---|
| IT基础设施层 | 包括硬件、软件、网络等基础设施以及提供咨询、规划和集成服务的企业,如:IBM,惠普、戴尔(数据中心服务);EMC(存储服务);微软、sun、redhat(虚拟化管理软件) |
| 数据源层 | 大数据生态圈里的数据提供者,是生物大数据、交通大数据、医疗大数据、政务大数据、电商大数据、社交网络大数据、搜索引擎大数据等各种数据的来源 |
| 数据管理层 | 包括数据提取、转换、存储和管理等服务的各种企业或产品,如:分布式u案例系统、ETL工具、数据库和数据仓库 |
| 数据分析层 | 包括分布式计算、数据挖掘、统计分析等服务的各种企业或产品,比如:分布式处理框架、统计分析软件、数据挖掘软件、数据可视化、BI工具 |
| 数据平台层 | 包括提供数据分享平台、数据分析平台、数据租赁平台等服务的企业或产品 |
| 数据应用层 | 提供智能交通、智慧医疗、智能物流、智能电网等行业应用的企业、机构和政府部门 |
云计算的关键技术:虚拟化、分布式存储、分布式计算、多租户等
物联网关键技术:识别和感知技术、网络与通信技术、技术挖掘和融合技术等
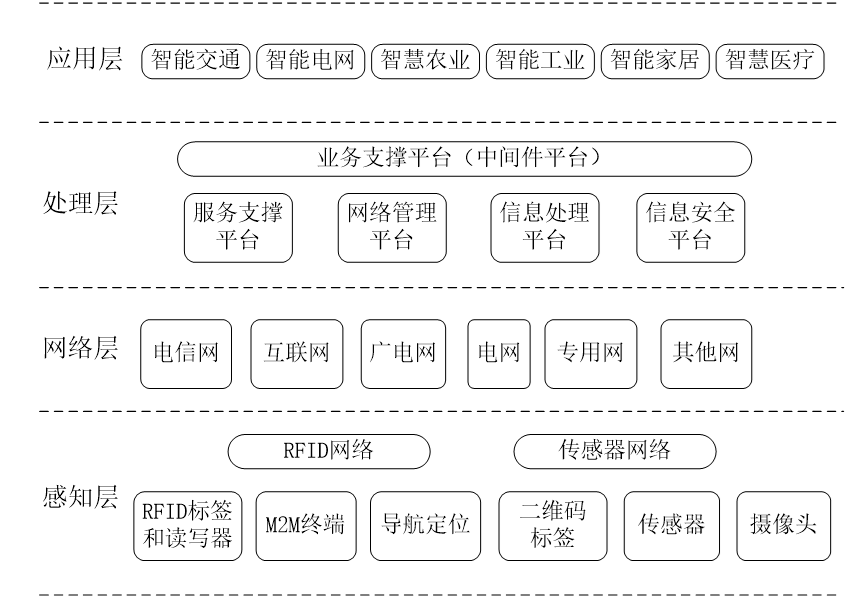
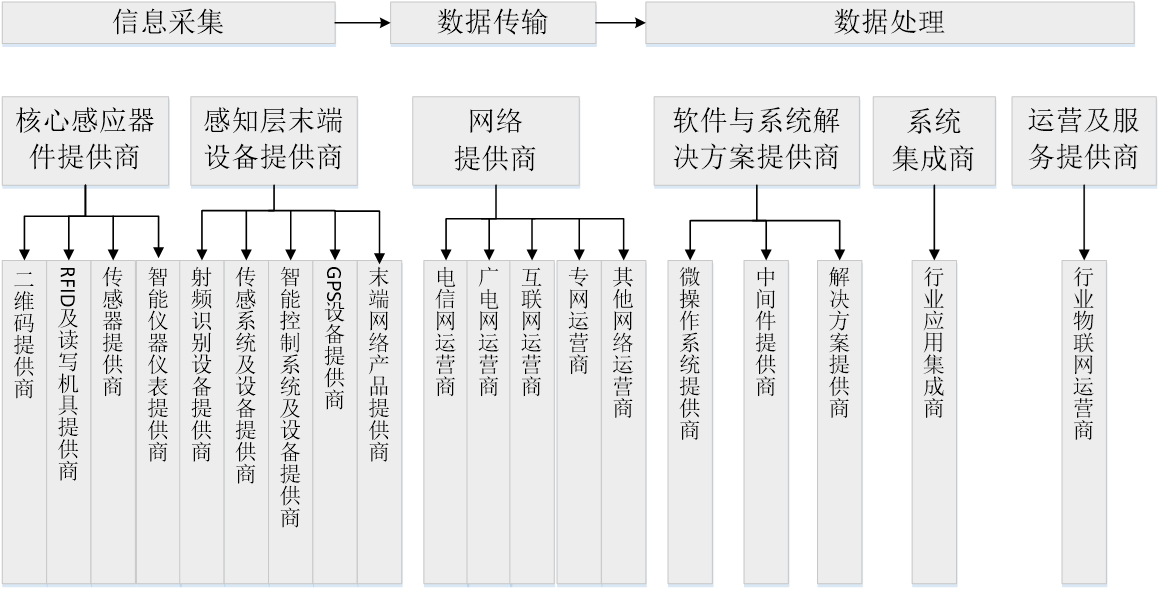
物联网产业链:核心感应器提供商、感知层末端设备、网络提供商、软件和行业解决方案、系统集成商、运营、服务提供商
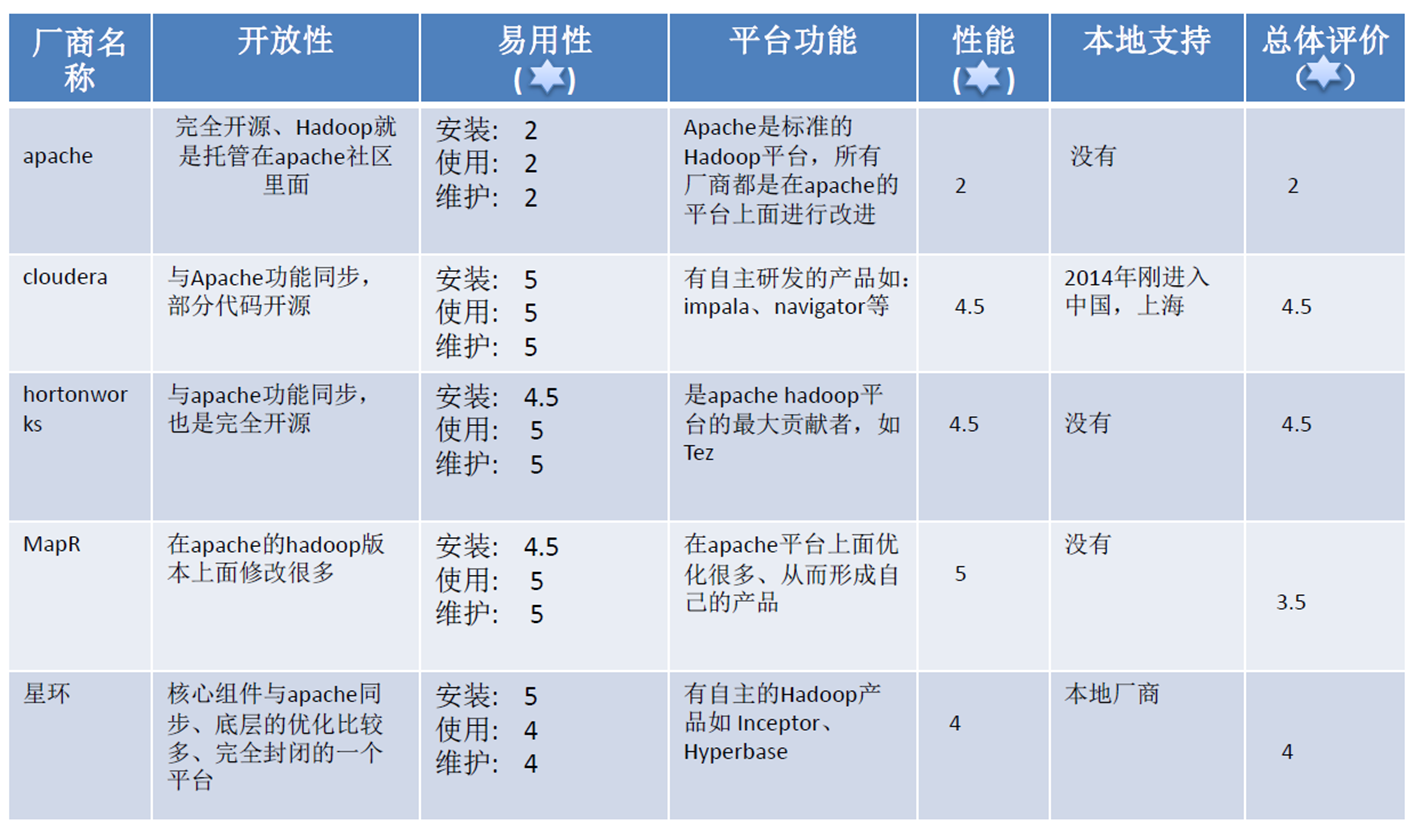
大数据处理框架Hadoop
具有以下优势:可靠高效可伸缩
各个版本的可用性:
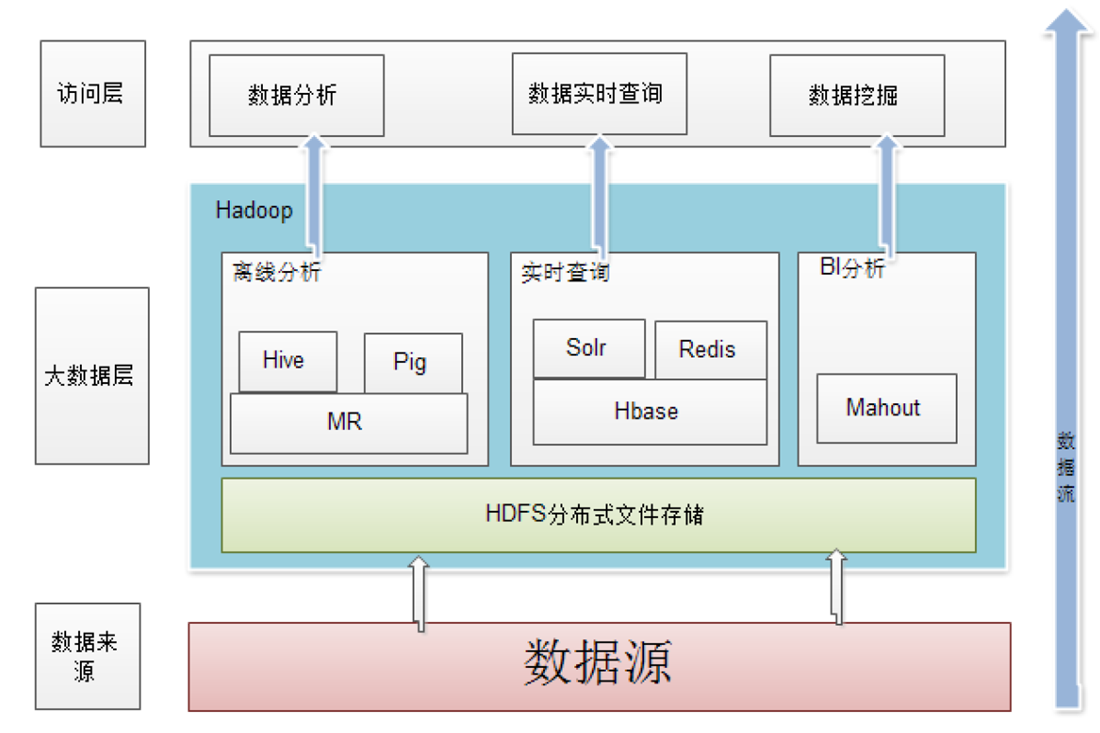
Hadoop应用架构图:
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| mapreduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行再yarn之上的下一代Hadoop查询处理框架 |
| Hive | hadoop之上的是数据仓库 |
| Hbase | Hadoop上的非关系型的分布式数据库 |
| pig | 一个基于Hadoop的大规模数据分析平台,提供类似于SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息的系统,可以处理消费者规模的网站中的所有动作流动作数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
Hadoop集群的节点类型:
- NameNode:负责协调集群中的数据存储
- DataNode:存储被拆分的数据块
- JobTracker:协调数据计算服务
- Tasktracker:负责执行由JobTracker指派的任务
- SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
unfinished