高级计算机体系结构
计算机介绍
- Moore's law: 集成电路上的二极管数量每两年翻一倍( SoC, MPSoC )
- Power Wall: all eletrical power consumed enventually radiated as heat. Why OR Answer: 1. use mutilple cores with lower frequency to obtain same performance. 2. packing more transistors needs deeper sub micro CMOS techniques which results in larger leakage current. 3. 关闭空闲核心, 动态电压-频率调整(DVFS),超频
- Pin Wall
Formulas: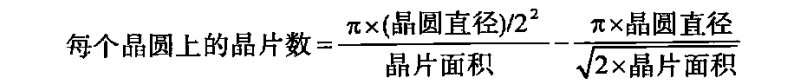

能耗动态 = 容性负载 * 电压^2
动态能耗功率 = 1/2 * 容性负载 * 电压^2
集成电路成本 = (晶片成本 + 晶片测试成本 + 封装与最终测试成本)/ 成本率
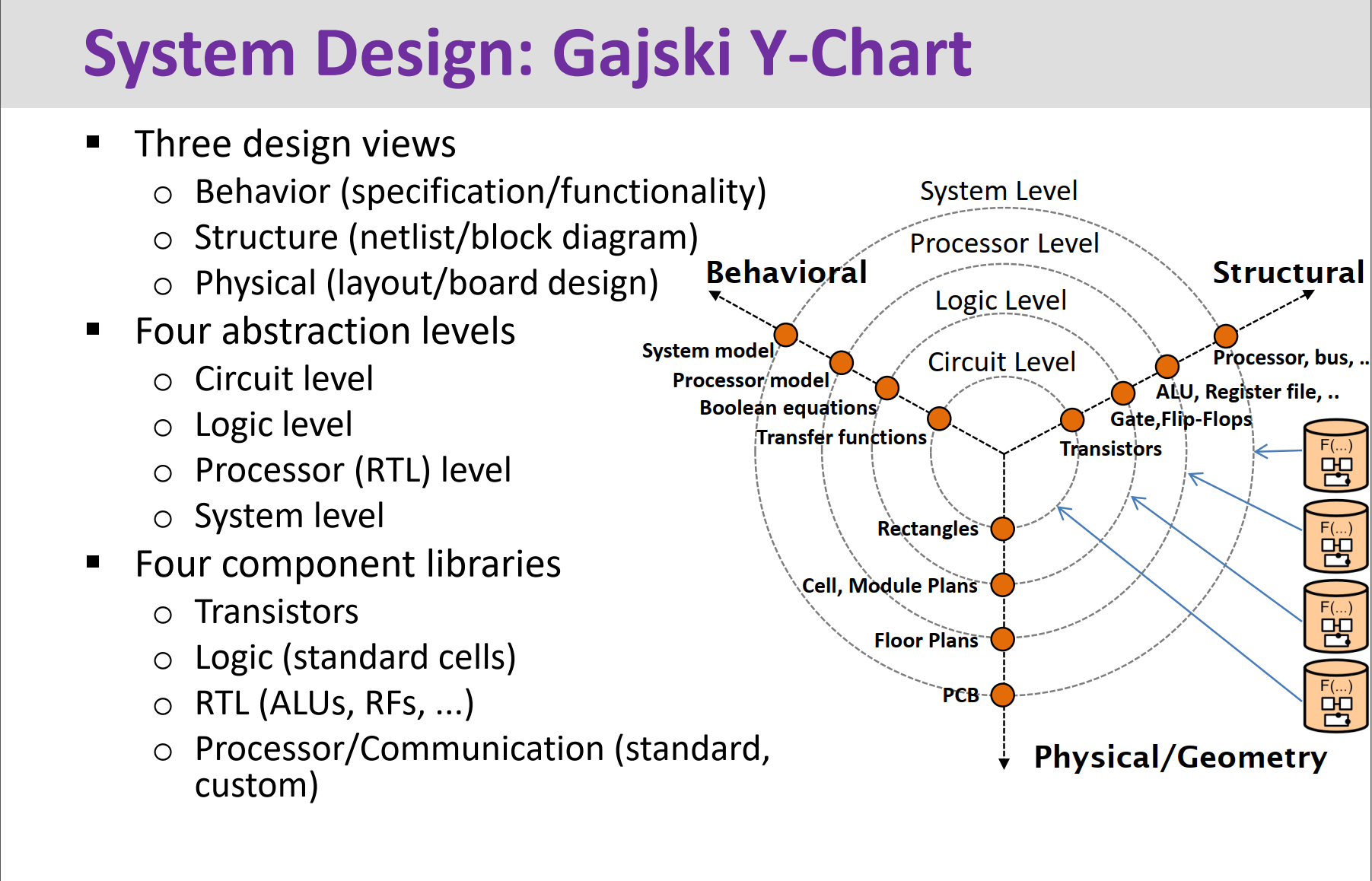
- System Design:GajskiY-chart
计算机性能
- 执行时间:墙时间(响应时间:处理、IO、空闲时间)
CPU时间:分摊IO时间,包括USER和SYSTEM两种CPU时间

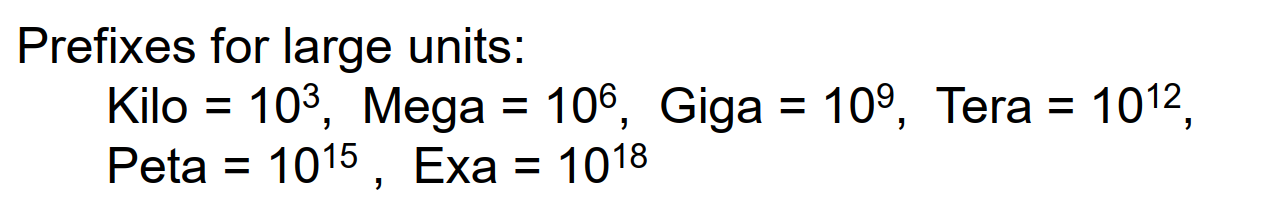
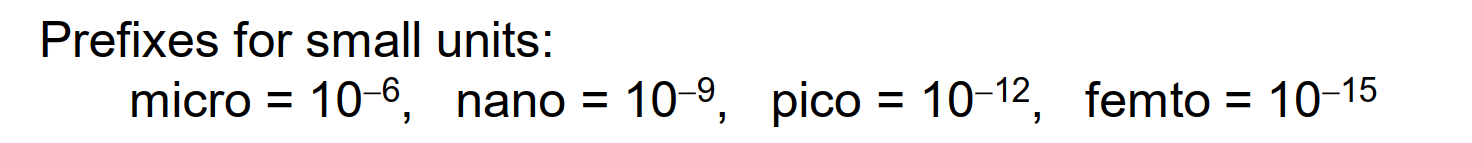
性能评估
- measurement、simultaion、formal analysis、statistics
- application mapping hardware
- 静态分析模型:数学等式,通过系统参数来计算,快但不准
- 动态分析模型:combination of 静态模型和动态模型,存在的方法:经典实时调度理论、统计排队理论、非确定性排队理论
- 仿真:基于轨迹的仿真,软件转化成抽象模型,将抽象模型根据结构展开并映射好,对展开模型进行模拟
- 时间、能耗、温度、空间、花费、其他(如噪音)、性能、
- 性能取舍:映射(对软件针对特定架构进行映射),架构(改变硬件平台),软件(改变软件实现,并行,分组)
- 为什么MPSoC难以测量?运行难以估计,非确定的,访存,通信延迟,处理计算过程不清楚,复杂的资源调度与共享交互
- 评估应该包括子系统及其之间的交互,计算、交流、内存、动态调度
缓存recap
- memory hierachy: direct map, set associate, fully associate, write policy, replacement policy

指令并行和开发(硬件优化和编译器优化)
- 流水线CPI = 理想CPI + 结构冒险stall + 数据冒险stall + 控制冒险stall
- 循环并行:unroll loop和SIMD -?数据依赖
- 名称依赖,数据依赖,控制依赖
- strip mining: 先 n mod k次执行,然后 n/k次大循环执行
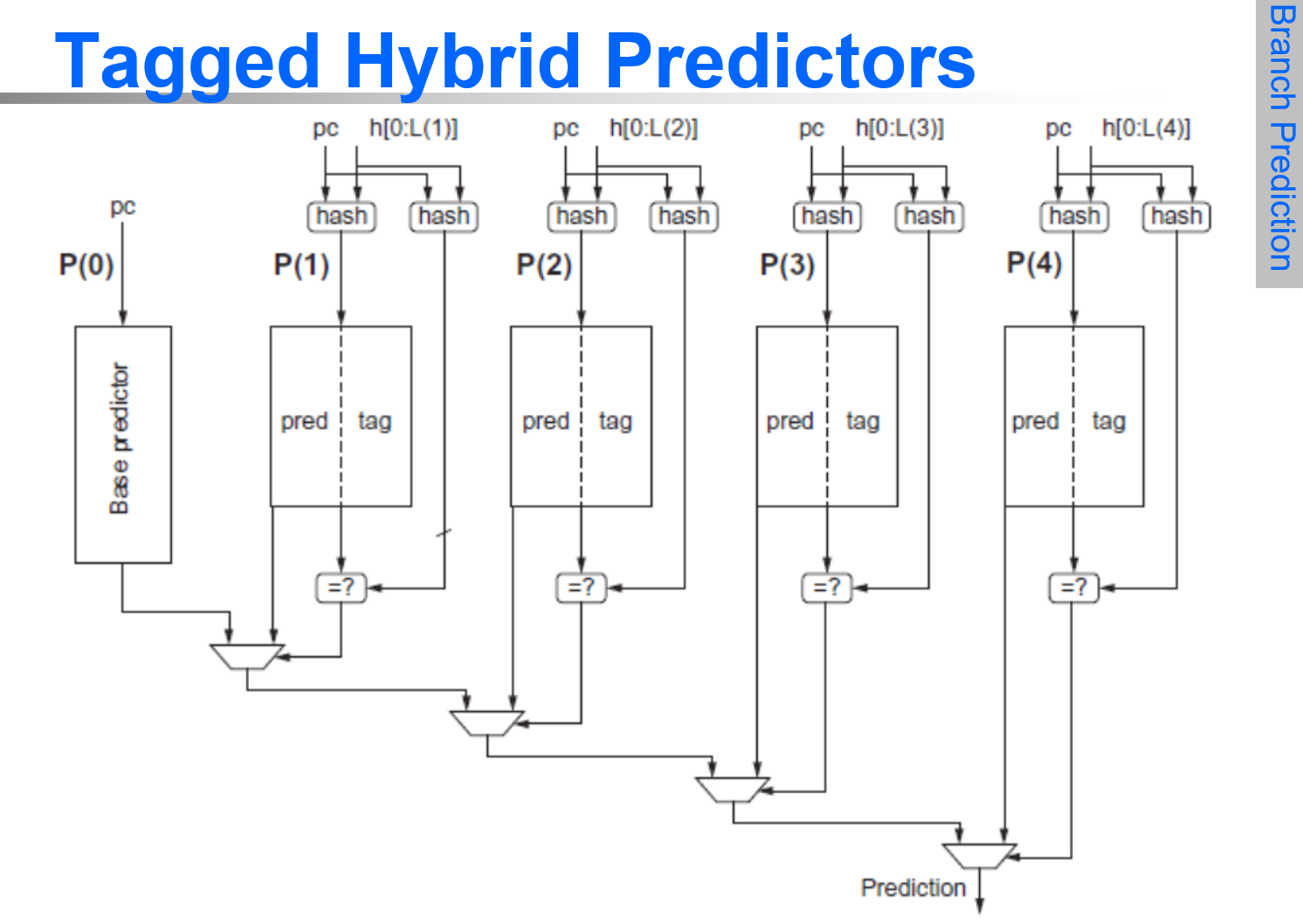
- 分支预测: 两bits预测器,相关联预测器(m,n),竞赛预测器(combine 相关联预测器和本地预测器),tagged hybrid预测器(每个分支和历史都需要一个预测器,问题:需要大量表 解决:hash tables)
- 动态调度:对指令执行过程重新安排来减少因保证数据流而引起的停顿(优势:编译器无关,能解决一些编译器无法解决的问题 劣势:硬件复杂度,复杂的异常处理)
- 动态调度:乱序执行&乱序完成两种
- 寄存器重命名:用来解决命名冲突,解决WAW。----only RAW remains
- Tomasulo's 方案:跟踪操作数&引用寄存器重命名(寄存器重命名通过保留站实现,保留站包括:指令、缓存的操作数值(when available)、提供操作数值的保留站号)
- Tomasulo’s 算法:发射(等保留站空&寄存器重命名)、执行、写回
- 基于硬件的推测:只有结果正确才提交结果,只有当指令不在是推测状态才能提交修改寄存器堆文件,因此需要额外硬件来避免在指令提交前出现任何不能恢复的操作 Re-order buffer:在完成状态和提交状态之间保存了指令结果(字段:指令类型、目标字段(寄存器编号)、值字段(输出值/指令运算结果)、状态字段(是否完成执行))
- 现代微处理器架构:动态调度、多发射、推测
- 分支目标缓存、返回地址预测器
数据并行,向量,单指令多数据,GPU
-
向量体系结构:(VMIPS)编译器可以在编译时告诉陈煦园是否可以ok。 多车道、向量遮罩寄存器、内存组、sride(conflict stall)、集中分散处理稀疏矩阵。
-
SIMD:指令指定的操作数少,因此寄存器堆也较小。运算密度:运行程序时所执行的浮点运算数除以在主存储器中访问的字节数;
-
图形处理器:网格是一组由线程块组成的代码(可向量循环),线程调度程序将线程块调度给执行该代码的处理器(处理器称之为多线程SIMD处理器,流式多处理器) warp:多SIMD处理器的线程调度器(包括:计分板),SIMD指令线程都自己的PC,硬件创建、管理、调度、执行的机器对象都是SIMD指令线程。
-
GPU分支硬件使用了:内部遮罩、分支同步、指令标记来控制分支何时分为多个执行路径,以及这些路径如何会和。 本地存储器:多线程SIMD处理器本地的片存储,整个GPU和所有线程块共享的片外DRAM成为GPU存储器。
-
convey:一组可以一起执行的向量指令
-
chimes(钟鸣):一个convey操作完;
-
向量运算时间:操作数向量的长度、操作数之间的结构冒险、数据相关。
-

-

-

高级计算机体系结构
https://blog.427221.xyz/archives/%E9%AB%98%E7%BA%A7%E8%AE%A1%E7%AE%97%E6%9C%BA%E4%BD%93%E7%B3%BB%E7%BB%93%E6%9E%84